News
- • July, 2022: You can download version 2 of our pretrained depth and surface normal models here (stronger than v1). For a live demo of these models on user uploaded images, please visit here.
- • July, 2022: ImageNet-3DCC is a part of Shift Happens (ICML 2022) benchmark now! The benchmark can be accessed from here. See the technical report here.
- • June, 2022: CVPR 2022 oral video is available below. You can reach the slides in Keynote and PDF formats here.
- • May, 2022: We applied 3D Common Corruptions to ImageNet and created the ImageNet-3DCC benchmark. It is also a part of the RobustBench now! Click here for a quickstart. The dataset can be accessed from here.
- • March, 2022: A live demo is available. Try your images on our depth and surface normal models!
Overview Video
Quick Summary

Using 3D information to generate real-world corruptions. The top row shows 2D corruptions applied uniformly over the image, e.g. as in Common Corruptions, disregarding 3D information. This leads to corruptions that are unlikely to happen in the real world, e.g. having the same motion blur over the entire image irrespective of distance from camera (top left). Middle row shows their 3D counterparts from 3D Common Corruptions (3DCC). The circled regions highlight the effect of incorporating 3D information. More specifically, in 3DCC, 1. motion blur has a motion parallax effect where objects further away from the camera seem to move less, 2. defocus blur has a depth of field effect, akin to a large aperture effect in real cameras, where certain regions of the image can be selected to be in focus, 3. lighting takes the scene geometry into account when illuminating the scene and casts shadows on objects, 4. fog gets denser further away from the camera, 5. occlusions of a target object, e.g. fridge (blue mask), are created by changing the camera’s viewpoint and having its view naturally obscured by another object, e.g. the plant (red mask). This is in contrast to its 2D counterpart that randomly discards patches.
The video below compares 2D and 3D corruptions for different queries and shift intensities.
Robustness in Real World
A New Set of Realistic Corruptions

The new corruptions. We propose a diverse set of new corruption operations ranging from defocusing (near/far focus) to lighting changes and 3D-semantic ones, e.g. object occlusion. These corruptions are all automatically generated, efficient to compute, and can be applied to most datasets. We show that they expose vulnerabilities in models and are a good approximation of realistic corruptions.
Key Aspects of Our Work
- • A challenging benchmark: We show that the performance of the methods aiming to improve robustness, including those with diverse data augmentation, reduce drastically under 3D Common Corruptions (3DCC). Furthermore, we observe that the robustness issues exposed by 3DCC well correlate with corruptions generated via photorealistic synthesis. Thus, 3DCC can serve as a challenging test bed for real-world corruptions, especially those that depend on scene geometry.
- • New 3D data augmentations: Motivated by this, our framework also introduces new 3D data augmentations. They take the scene geometry into account, as opposed to 2D augmentations, thus enabling models to build invariances against more realistic corruptions. We show that they significantly boost model robustness against such corruptions, including the ones that cannot be addressed by the 2D augmentations.
- • Easy to generate and extend: The proposed corruptions are generated programmatically with exposed parameters, enabling fine-grained analysis of robustness, e.g. by continuously increasing the 3D motion blur. The corruptions are also efficient to compute and can be computed on-the-fly during training as data augmentation with a small increase in computational cost. They are also extendable, i.e. they can be applied to standard vision datasets, such as ImageNet, that do not come with 3D labels.
Benchmarking with 3DCC
Non-Semantic Corruptions
- • The video below shows predictions of a baseline surface normals model degrading with corrupted inputs.
Semantic Corruptions
- • See also the predictions of a baseline segmentation model degrading with occlusions.
Quantitative Results
- • The figure below quantitatively shows the degraded performance for normals and depth estimation tasks under real-world corruptions approximated by 3DCC.
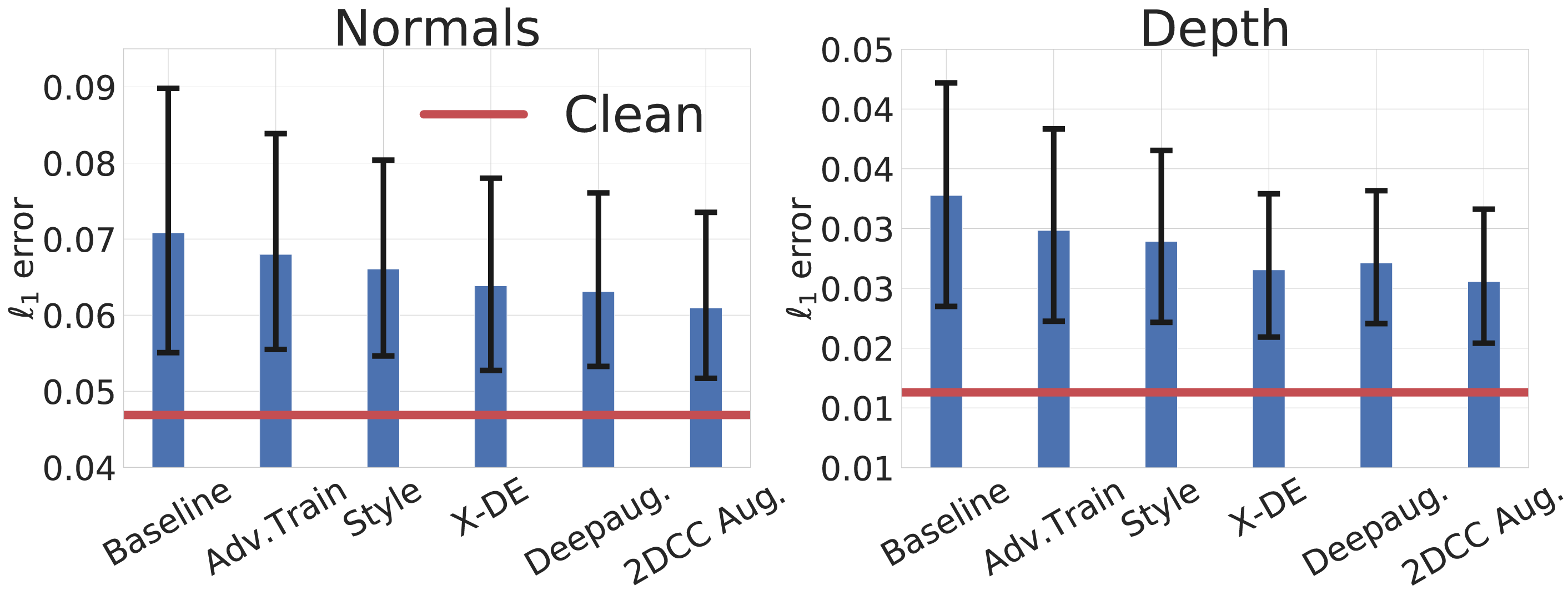
Existing robustness mechanisms are found to be insufficient for addressing real-world corruptions approximated by 3DCC. Performance of models with different robustness mechanisms under 3DCC for surface normals (left) and depth (right) estimation tasks are shown. Each bar shows the l1 error averaged over all 3DCC corruptions (lower is better). The red line denotes the performance of the baseline model on clean (uncorrupted) data. The results denote that existing robustness mechanisms, including those with diverse augmentations, perform poorly under 3DCC. Please see the paper for details.
- • Please see the paper for more results, e.g. evaluations performed to demonstrate that 3DCC can expose vulnerabilities in models that are not captured by 2DCC and the generated corruptions are similar to expensive realistic synthetic ones.
Applying 3DCC to Standard Vision Datasets

3DCC can be applied to most datasets, even those that do not come with 3D information. Several query images from the ImageNet and COCO dataset are shown above with near focus, far focus and fog 3D corruptions applied. Notice how the objects in the circled regions go from sharp to blurry depending on the focus region and scene geometry. To get the depth information needed to create these corruptions, predictions from MiDaS model is used. This gives a good enough approximation to generate realistic corruptions (as also analyzed in the paper).
- • ImageNet-3DCC & COCO-3DCC: See our repository which contains the scripts and depth data to apply 3DCC on ImageNet and COCO datasets.
- • ImageNet-3DCC is a part of the RobustBench now! Click here for a quickstart.
- • ImageNet-3DCC is also a part of the ICML 2022 Shift Happens Benchmark now! Click here for details.
Improving Robustness with 3D Data Augmentation

Qualitative results of learning with 3D data augmentation on random queries from OASIS, Adobe After Effects generated data, manually collected DSLR data, and in-the-wild YouTube videos for surface normals. The ground truth is gray when it is not available, e.g. for YouTube. Our predictions in the last row are noticeably sharper and more accurate compared to baselines. Please see the paper for more details.
We also evaluate the performance on several query videos. The predictions are made frame-by-frame with no temporal smoothing. Our model using the proposed augmentations is significantly more robust compared to baselines.
Live Demo & Pretrained Models (v2)
You can download the pretrained depth and surface normal models used in the live demo from here.
In case you use these pretrained models please cite the following papers:




